NLP for learners-Scraping the URLs from multiple pages in Python
In the previous post, we learned how to get the URLs of articles from the top page. However, the number of articles available from the top page is still very small. So I will show you how to improve the code and get more URLs from the top page.
Extract the list of articles from the calendar
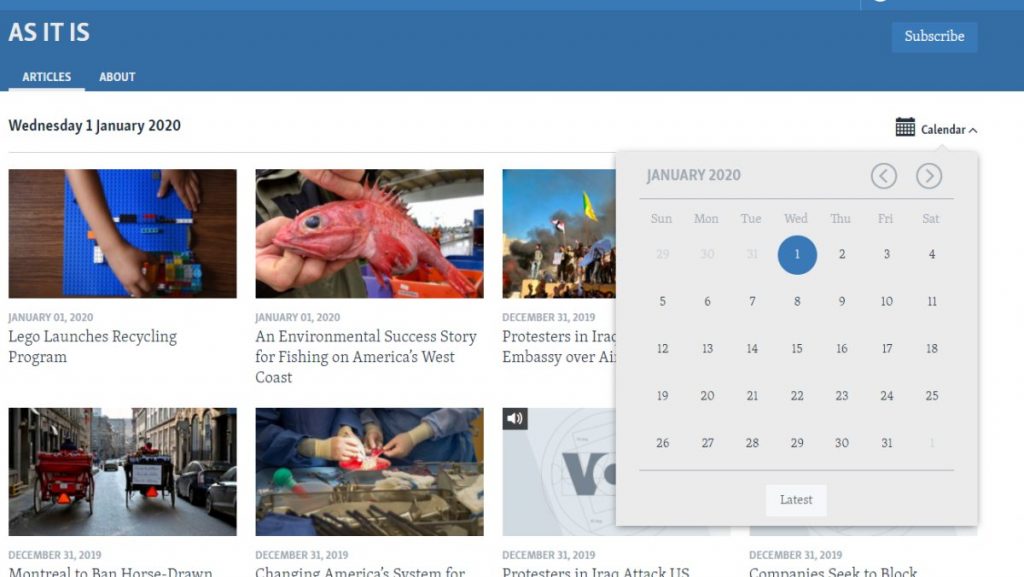
Go to the VOA Learning English website and go to the As it is category page. There is a calendar at the top right of the page, so we can go back to the past articles.
Let’s extract the articles in January 2020.
First, create a text file with the URLs of the pages by date and save it as url_by_date.txt.
https://learningenglish.voanews.com/z/3521/2020/1/1
https://learningenglish.voanews.com/z/3521/2020/1/2
https://learningenglish.voanews.com/z/3521/2020/1/3
....
https://learningenglish.voanews.com/z/3521/2020/1/30
https://learningenglish.voanews.com/z/3521/2020/1/31Create 31 lines of text in total.
Next, we will extract the URLs of the articles based on this list.
with io.open('url_by_date.txt', encoding='utf-8') as f:
url = f.read().splitlines()Read the text file url_by_date.txt that we created above. After opening the file and naming it f, .read() is used to read the file. .splitlines() allows you to split the text into line segments. As you can see, Python allows you to write multiple operations in a chain.
The split lines of text are stored in a list url. Since there are 31 lines of text, each URL is stored in url[0]–url[30].
url[0] = 'https://learningenglish.voanews.com/z/3521/2020/1/1
'
url[1] = 'https://learningenglish.voanews.com/z/3521/2020/1/2
'
url[2] = 'https://learningenglish.voanews.com/z/3521/2020/1/3
'
....
url[29] = 'https://learningenglish.voanews.com/z/3521/2020/1/30
'
url[30] = 'https://learningenglish.voanews.com/z/3521/2020/1/31'We can create a list of URLs for articles by iterating through the for statement.
for date in range(len(url)):url ranges from url[0]–url[30], so len(url)=31. That is, date varies from 0 to 30.
res = requests.get(url[date])
soup = BeautifulSoup(res.text, 'html.parser')
elems = soup.find_all(href=re.compile("/a/"))requests.get() extracts the html string in order. It only extracts the html, so you can pass it to BeutifulSoup and extract only the ones containing “/a/” and store them in elem.
for i in range(len(elems)):
links.append('https://learningenglish.voanews.com'+elems[i].attrs['href'])
We remove the tags by elems[i].attrs['href'] and extract the URL string only. And we attach the domain name part to this string and append it to links.
print(str(date+1)+' / '+str(len(url))+' finished')
Displays the progress of the program.
When you run the program, the following message will be displayed.
1 / 31 finished
2 / 31 finished
3 / 31 finished
....
31 / 31 finishedRemove duplicate URLs and combines the fetched URLs into a single string and writes it to a file.
links = np.unique(links)
text='\n'.join(links)
with io.open('article-url.txt', 'w', encoding='utf-8') as f:
f.write(text)Here’s the entire code.
import numpy as np
import requests
from bs4 import BeautifulSoup
import io
import re
with io.open('url_by_date.txt', encoding='utf-8') as f:
url = f.read().splitlines()
links = []
for date in range(len(url)):
res = requests.get(url[date])
soup = BeautifulSoup(res.text, 'html.parser')
elems = soup.find_all(href=re.compile("/a/"))
for i in range(len(elems)):
links.append('https://learningenglish.voanews.com'+elems[i].attrs['href'])
print(str(date+1)+' / '+str(len(url))+' finished')
links = np.unique(links)
text='\n'.join(links)
with io.open('article-url.txt', 'w', encoding='utf-8') as f:
f.write(text)https://learningenglish.voanews.com/a/5225652.html
https://learningenglish.voanews.com/a/5225655.html
https://learningenglish.voanews.com/a/5226969.html
....199 URLs were extracted.
SNSでシェア