NLP for learners-Scraping the article from the URL and saving it to the hard drive with BeautifulSoup
In the previous post, we created a list of URLs from the website.
We will extract the text of the article based on this list.
Use the selector to extract the relevant part
with io.open('article-url.txt', encoding='utf-8') as f:
urls = f.read().splitlines()In the previous post, we saved the URLs of the articles from VOA Learning English for a month to article-url.txt. We read it out and .splitlines() split it into lines and store them as list url.
urls[0]='https://learningenglish.voanews.com/a/5225652.html
'
urls[1]='https://learningenglish.voanews.com/a/5225655.html'
urls[2]='https://learningenglish.voanews.com/a/5226969.html
'
......Iterate through the for statement and extract the text of the body for each URL.
for i in range(len(urls)):There are 199 URLs stored in the text file, so len(urls)=199. i varies from 0 to 198 and repeats the process.
try:
res = requests.get(urls[i], timeout=3.0)
except Timeout:
print('Connection timeout')
continue
soup = BeautifulSoup(res.text, "html.parser")
requests.get() extracts the html and passes it to BeutifulSoup. requests.get() just extracts the html and we need to pass the data to BeutifulSoup which analyzes the html.
try: executes requests.get() once and if there is no response from the server for 3.0 seconds (timeout=3.0), it executes except timeout:. Here, it simply returns to the beginning of the for statement with continue and processes the next URL.
elems = soup.select('#article-content > div.wsw > p')This line is the key part of the code. soup.select() specifies a selector to extract only certain parts of the html and store them in the list elems.
Identify the selector
Selectors require knowledge of HTML and CSS. A website is generally divided into several blocks such as header, menu, article heading, body and footer. Each block has an ID or class to identify it, and the font and color are specified based on those IDs.The part that designates these blocks is called a selector.
On the VOA Learning English website, the selector for the body of an article is #article-content > div.wsw > p. In HTML, this would look like the following.
Selectors require knowledge of HTML and CSS. A website is generally divided into several blocks such as header, menu, article heading, body and footer. Each block has an ID or class to identify it, and the font and color are specified based on those IDs.The part that designates these blocks is called a selector.
On the VOA Learning English website, the selector for the body of an article is #article-content > div.wsw > p. In HTML, this would look like the following.
<div id="article-content">
<div class="wsw">
<p>本文</p>
</div>
</div> The chrome browser makes it easy to get to know the selector.
Right-click the mouse on the body and select “Verification”.
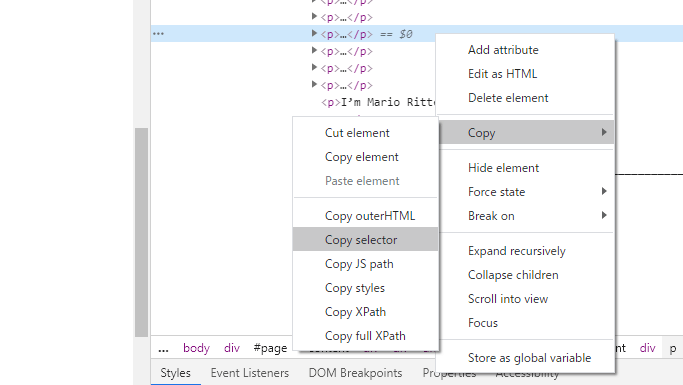
As the HTML is displayed on the right side of the screen, right-click on the blue line again. Then click Copy –> Copy selector to copy the selector string to the clipboard.
Actually, the selector string will be copied such as article-content > div.wsw > p:nth-child(13), but :nth-child(13) is not necessary.
Combine and save the extracted text
if not len(elems) == 0:
for j in range(len(elems)):
chars.append(str(elems[j]))
char = ' '.join(chars)
Some URLs in the list of URLs extracted in article-url.txt do not include the text. This is because some of the URLs have no text and contain only audio. If there is no item corresponding to the specified selector, the number of elements in the elems will be 0.
So the elems are concatenated only if the number of elements is non-zero. if not len(elems) == 0: means “if the number of elements in the elems is non-zero”.
To avoid the error, str() is used to convert it into a string and add it to the list texts.
Also, .join() combines the list chars into a single string char.
index = char.find('_______________')
if not index == -1:
texts.append(char[:index])
else:
texts.append(char)Remove any explanations of English phrases that are included at the end of the text. Use the string '___' as a clue to separate sections.
.find() returns the position of the specified string and stores it in index. If the string is not included, it returns -1.
char[:index] is from the beginning of the string to one before '___'. If index is not -1, it removes the phrase description section and adds the string to the list texts.
If index is -1, the entire string is added to the list text.
text = ' '.join(texts)
Combines list texts into a single string text.
p = re.compile(r"<[^>]*?>")
text = p.sub("", text)
Since the extracted text contains tags, we use regular expressions to remove them. re.compile() sets the rules for regular expressions and .sub() removes them.
text = re.sub('[“”,—]()','', text)
If any of the characters in '[""",-]()' are true, delete them.
p = re.compile("\.\s+?([A-Z])")
text = p.sub(" eos \\1", text)
Replace a period at the end of a sentence with the symbol for sentence termination, eos. Here, we use a pair of periods, spaces, and uppercase letters to determine the end of a sentence.
text = text.lower()
.lower() converts characters to lowercase.
with io.open('articles.txt', 'w', encoding='utf-8') as f:
f.write(text)Combine the list to make a string text and save it in the file articles.txt.
The content of article.txt is as follows.
The Australian government said this week it will spend over 34 million dollars on helping wildlife recover from
......Here’s the whole code.
import numpy as np
import requests
from requests.exceptions import Timeout
from bs4 import BeautifulSoup
import io
import re
with io.open('article-url.txt', encoding='utf-8') as f:
urls = f.read().splitlines()
texts = []
for i in range(len(urls)):
try:
res = requests.get(urls[i], timeout=3.0)
except Timeout:
print('Connection timeout')
continue
soup = BeautifulSoup(res.text, "html.parser")
elems = soup.select('#article-content > div.wsw > p')
chars = []
if not len(elems) == 0:
for j in range(len(elems)):
chars.append(str(elems[j]))
char = ' '.join(chars)
index = char.find('_______________')
if not index == -1:
texts.append(char[:index])
else:
texts.append(char)
print(str(i+1)+' / '+str(len(urls))+' finished')
text = ' '.join(texts)
p = re.compile(r"<[^>]*?>")
text = p.sub("", text)
text = re.sub('[“”,—]()','', text)
p = re.compile("\.\s+?[A-Z]")
text = p.sub(" eos ", text)
text = text.lower()
with io.open('articless.txt', 'w', encoding='utf-8') as f:
f.write(text)SNSでシェア